Understanding the Name, Structure, and Loss Function of the Variational Autoencoder
Despite the intuitive appeal of variational autoencoders (VAEs), their underlying principles can be elusive. After extensive research across papers and online resources, I will summarize the core insights behind the VAE's name, structure, and loss function and try to explain how the mathematical formulas used to describe the VAE came into being from first principles, as opposed to simply providing interpretations for them.
Basics of VAEs
VAEs are probabilistic generative models, when trained on a dataset \(X\), allow us to sample from a latent variable \(Z\) and generate output resembling samples in \(X\) through a trained neural network \(f: Z \rightarrow X\).
This can be formulated as making the probability of generating \(X = x\) as close as possible to the actual \(P(X = x)\) (known quality) under the entire generative process.
Ideal Training Goal
In the ideal situation, based on the marginal distribution formula we have \(P(X = x) = \int{P(X = x | Z = z) P(Z = z) dz}\). Thus, the training goal of variational autoencoders is to make the actual \(\int{P(X = x | Z = z) P(Z = z) dz}\) as close to \(P(X = x)\) as possible.
Latent Variable Distribution
VAEs select a multivariate normal distribution for the latent variable \(Z\) based on the principle that any distribution in \(d\) dimensions can be generated by mapping normally distributed variables through a sufficiently complicated function, which could be approximated using the neural network \(f: Z \rightarrow X\) we train.
Approximation Challenge
Having reasonably decided \(Z \sim N(0, I)\), we may calculate the actual \(\int{P(X = x | Z = z) P(Z = z) dz}\). This is straightforward to approximate: we can randomly sample a large number of \(Z\) values \(\{z_1, \dots, z_n\}\), and approximate \(\int{P(X = x | Z = z) P(Z = z) dz}\) as \(\sum_{j}^{n}{P(X = x | Z = z_j)}\).
However, for most \(Z\) values, \(P(X = x | Z)\) will be nearly zero, contributing almost nothing to our calculation. This is especially the case in high dimensional spaces, for which an extremely large number of samples of \(Z\) may be required.
To address the problem, we can attempt to sample values of \(Z\) that are likely to have produced \(X = x\) and compute \(\int{P(X = x | Z = z) P(Z = z) dz}\) just from those.
The "Variational" Aspect:
To do so, we can fit another parametrized function \(Q(Z | X = x)\), which can give us a distribution over \(Z\) values that are likely to produce \(X = x\) through \(f: Z \rightarrow X\) given \(X = x\). This is an example of a variational Bayesian method, which involves finding an "optimal" function (a task known as variational calculus) and is the source of the word "variational" in variational autoencoders.
Minimizing Divergence
Theoretically, the values of \(Z\) that are likely to have produced \(X = x\) follow the conditional distribution \(P(Z | X = x)\). Thus, our original goal of making the actual \(\int{P(X = x | Z = z) P(Z = z) dz}\) as close to \(P(X = x)\) as possible can be transformed to minimizing the Kullback-Leibler divergence between \(P(Z | X = x)\) and \(Q(Z | X = x)\):
\[KL(Q(Z | X = x) || P(Z | X = x)) = \int{Q(Z = z | X = x) \log{\frac{Q(Z = z | X = x)}{P(Z = z | X = x)}} dz}\]
According to Bayes' Law,
\[P(Z = z | X = x) = \frac{P(X = x | Z = z) P(Z = z)}{P(X = x)}\]
Thus, we have:
\[\int{Q(Z = z | X = x) \log{\frac{Q(Z = z | X = x) P(X = x)}{P(X = x | Z = z) P(Z = z)}} dz}\]
\[= \int{Q(Z = z | X = x) (\log{\frac{Q(Z = z | X = x)}{P(Z = z)}} + \log{P(X = x)} - \log{P(X = x | Z = z)}) dz}\]
\[= \int{Q(Z = z | X = x) \log{\frac{Q(Z = z | X = x)}{P(Z = z)}} dz} + \int{Q(Z = z | X = x) \log{P(X = x)} dz} - \int{Q(Z = z | X = x) \log{P(X = x | Z = z)} dz}\]
Note that:
\[\int{Q(Z = z | X = x) \log{\frac{Q(Z = z | X = x)}{P(Z = z)}} dz} = KL(Q(Z | X = x) || P(Z))\]
\[\int{Q(Z = z | X = x) \log{P(X = x)} dz} = \log{P(X = x)} \int{Q(Z = z | X = x)} dz = \log{P(X = x)}\]
Thus, we have:
\[KL(Q(Z | X = x) || P(Z | X = x)) = KL(Q(Z | X = x) || P(Z)) + \log{P(X = x)} - \int{Q(Z = z | X = x) \log{P(X = x | Z = z)} dz}\]
As \(\log{P(X = x)}\) is constant, if we were to minimize \(KL(Q(Z | X = x) || P(Z | X = x))\), we should minimize:
\[KL(Q(Z | X = x) || P(Z)) - \int{Q(Z = z | X = x) \log{P(X = x | Z = z)} dz}\]
To further transfer that into a calculatable function, we need to be more specific about the form that \(Q(Z | X)\) will take. The usual choice is to say that \(Q(Z | X = x) = N(Z | \mu(X = x), \Sigma(X = x))\), i.e., \(Q(Z | X = x)\) follows a Gaussian distribution where the mean and covariance matrix are calculated by parameterized functions (trained neural networks) given \(X = x\). In this case, fitting \(Q(Z | X = x)\) involves training these neural networks.
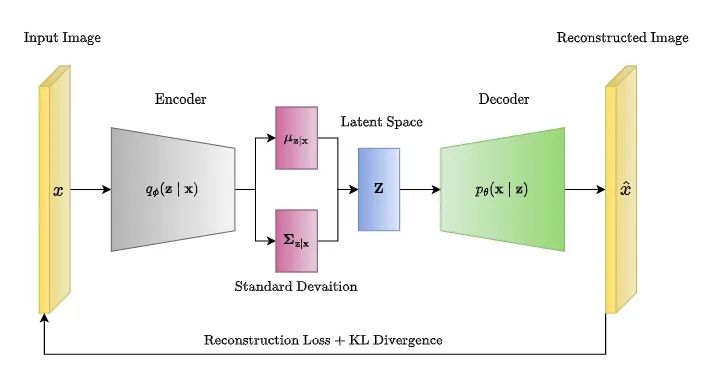
The advantages of this choice are computational, as \(KL(Q(Z | X = x) || P(Z)) + \log{P(X = x)}\) is now a KL-divergence between two multivariate Gaussian distributions, which can be computed in closed form.
As for \(\int{Q(Z = z | X = x) \log{P(X = x | Z = z)} dz}\), it depicts the expected log-likelihood of generating \(X = x\) as the VAE's output through \(f(Z)\) when sampling from \(Q(Z = z | X = x)\) given \(X = x\). Thus, it can be treated as the "reconstruction loss" of the VAE, and different closed-form indices, such as mean square error, may be used as proxies of it depending on the project domain.
Why "Autoencoders"?
Despite the mathematical basis of VAEs being quite different from classical autoencoders, they are named "autoencoders" due to their final training objective involving an encoder (the neural networks \(\mu\) and \(\Sigma\) determining mean and covariance) and a decoder (the neural network \(f\)), which resembles a traditional autoencoder in structure.
References
- https://arxiv.org/abs/1606.05908
- https://agustinus.kristia.de/techblog/2016/12/10/variational-autoencoder/
- https://arxiv.org/abs/1312.6114
- https://arxiv.org/abs/1907.08956
- https://stats.stackexchange.com/questions/485488/should-reconstruction-loss-be-computed-as-sum-or-average-over-input-for-variatio
- https://stats.stackexchange.com/questions/540092/how-do-we-get-to-the-mse-in-the-loss-function-for-a-variational-autoencoder
- https://stats.stackexchange.com/questions/464875/mean-square-error-as-reconstruction-loss-in-vae
- https://stats.stackexchange.com/questions/323568/help-understanding-reconstruction-loss-in-variational-autoencoder