Paper Reading: Precise Interprocedural Dataflow Analysis via Graph Reachability
NOTE: This is a Paper Reading for Topics in Programming Languages: Automated Testing, Bug Detection, and Program Analysis. The original paper can be found here.
To be honest, I found the paper to be almost unreadable due to it being full of unfamiliar concepts and abstract formalizations. I tried my best to do some studying into the topic so that I can understand the problem that they are trying to solve, and important aspects of their algorithm, better.
Graph Reachability
Graph Reachability means whether it is possible to get from one vertex to another vertex within a graph.
In an Undirected Graph \(G(V, E)\), Graph Reachability between one pair of nodes can be calculated using Breadth-First Search, while Graph Reachability between all pair of nodes can be reduced to calculating the Connected Components of the Undirected Graph, which is an efficient algorithm with \(O(|V| + |E|)\) time complexity.

In a Directed Graph, Graph Reachability between one pair of nodes can also be calculated using Breadth-First Search. However, there is no efficient algorithm that can calculate Graph Reachability between all pair of nodes for all Directed Graphs.
For any Directed Graph, calculating Graph Reachability between all pair of nodes can be reduced to calculating All Pairs Shortest Distance using the Floyd-Warshall Algorithm, which has an \(O({|V|}^3)\) time complexity.
More efficient algorithms are only applicable to Planar Directed Graphs.
Data Flow Analysis
Constant Propogation (determining whether variables at a given point in the program are guaranteed to have constant values) and Live Variable Analysis (determining at a given point in the program, which variables might be used before being overwritten) are two commonly encountered examples of Data Flow Analysis.
Given a program's Control Flow Graph, Data Flow Analysis:
- Associates each Node of the Control Flow Graph with Information concerning the Variables within that Node (known as Dataflow Fact's, usually a Mapping between Variables and their Values or Properties)
- Models the effect of executing a Node with a Dataflow Function.
In most Data Flow Analysis problems, we take one of the following approaches to obtain the Dataflow Facts for each Node:
- Summarizing paths entering the Node from the Start, such as in Constant Propogation. Known as "Forward Problem"'s.
- Summarizing paths exiting the Node from the Exit, such as in Live Variable Analysis. Known as "Backward Problem"'s.
How we summarize paths is known as the Confluence Operator.
Data Flow Analysis problems can also be divided into "may" problems and "must" problems.
- In "may" problems, the Dataflow Facts for each Node include information about what may be true. An example is Live Variable Analysis, where we determine whether a variable may be used before being overwritten in a given point in the program.
- In "must" problems, the Dataflow Facts for each Node include information about what must be true. An example is Constant Propogation, where we determine whether a variable must have a given value in a given point in the program.
Many interesting Data Flow Analysis problems, such as Live Variable Analysis, can be modeled as GEN/KILL problems, or bit-vector problems, in which:
- A set of variables, \(KILL[n]\), is defined at Node \(n\).
- A set of variables, \(GEN[n]\), is used at Node \(n\).
- We use Union or Intersection to summarize paths entering a Node to obtain the Dataflow Facts for the Node.
Interprocedural Dataflow Analysis
The goal of Interprocedural Dataflow Analysis is to capture an Abstraction of the Effect of calling a Procedure in Dataflow Analysis.
A naive approach to Interprocedural Dataflow Analysis is to reduce it to Intraprocedural Dataflow Analysis in some way.
- Procedure Inlining
- Exponentially increases the Control Flow Graph
- Cannot handle recursion
- Context Sensitive Procedure Inlining
- Uses Context Information (often an Approximation of the Call Stack) to distinguish between different Calls of the same Procedure, and reduce the number of inlined Procedures.
However, even after research, I have failed to understand the more complicated approaches (as well as the approaches proposed in this Paper).
I can only get the point that the author shows that many Interprocedural Dataflow Analysis problems, in which:
- A finite set of Dataflow Facts
- Dataflow Functions distribute over the Confluence Operator (which I don't fully understand)
including GEN/KILL problems, or bit-vector problems, can be reduced to a Graph Reachability Problem on a Directed Graph.
Furthermore, I believe the main contribution of this paper is theoretical, but what is its value in real-world Dataflow Analysis problems, especially considering that the Time Complexity of Graph Reachability Problems on Directed Graphs are high?
I honestly hope that I can get some insight into these approaches during our class on Monday. Thank you!
Feedback from the Class Discussion
Some of the paper's idea comes from Abstract Interpretation. It is nice theoretically, but it is far from implementation.
Graph Reachability in the context of Interprocedure Analysis is also known as Context-Free Language Reachability and Dyck Reachability.
In the context of this paper, there are multiple Dataflow Functions, one for each Node in the Control Flow Graph. Given a Node in the Control Flow Graph, we use Pattern Matching to determine what its Dataflow Function is. Lambdas are used to represent these Dataflow Functions. Explanation for the notations: \(\lambda <parameters>.<return\_value>\) means def f(<parameters>): return <return_value>.
In the context of this paper, we require all Dataflow Functions to be distributive over the Meet Function (Confluence Function). This means that, given the Meet Function \(\Pi\) and a Dataflow Function \(f\), \(f(X~\Pi~Y) = f(X)~\Pi~f(Y)\) for any two Dataflow Facts \(X, Y\).
Each Dataflow Function can be visualized using a Graph Representation. The Edges represent Dependencies between Facts of the Variables in the Old Dataflow Facts and Facts of the Variables in the New Dataflow Facts.
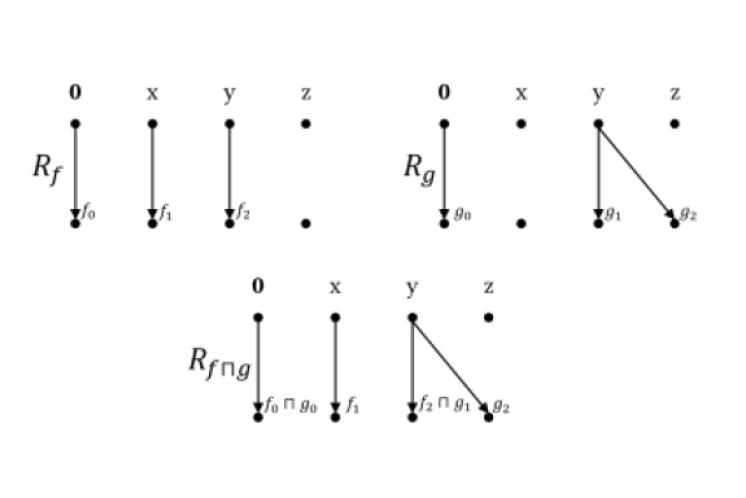
x is Shorthand for the Facts of xWorklist Algorithm: an Algorithm which takes Objects from a Worklist (a Queue of some sort) one at a time, processes it in some way, and perhaps further adds new Objects to the Worklist, until some Target is reached. Example: Breadth First Search.