Paper Reading: ReCrash: Making Software Failures Reproducible by Preserving Object States
NOTE: This is a Paper Reading for Advanced Software Engineering. The original paper can be found here.
Background
Reproduction is key to finding and fixing software problems and verifying proposed solutions, but reproduction can be difficult.
- Nondeterminism: A problem may depend on timing (e.g., context switching), memory layout (e.g., hash codes), or random number generators.
- Remote detection: A problem may be discovered by someone other than the developer, and it may depend on implicit program inputs such as user GUI actions, environment variables, the state of the file system, operating system behavior, etc. This information may be easy to miss, difficult to collect, or confidential.
- Test case complexity: The exposing execution might be complex, and the buggy method might be called multiple times before the bug is triggered.
Proposed Solution: ReCrash
ReCrash maintains a shadow stack with copies of the receiver and arguments to each method during execution of the target program.
- Several copy strategies
- Several optimizations
When the program crashes, ReCrash serializes the shadow stack, and generates unit tests by calling each method on the shadow call stack with their receiver and arguments.
- Calling the method at top of the call stack may not provide enough context.
- Calling a method closer to the bottom provides more context, but is less likely to reproduce the original failure.
Proposed Solution: ReCrash
Assumption:
- It is possible to reproduce many failures with only some of the information available on entry to the methods on the stack at the time of the failure.
- Many bugs are dependent on small parts of the heap.
- Good object-oriented style encapsulates important state nearby.
- Good object-oriented style avoids excessive use of globals.
- ReCrash has access to and will store any parts of the global state or environment that are passed as method arguments.
Question: What if global state is read or written in the method?
Monitoring Phase
- Several copy strategies
- Several optimizations
- Monitoring fewer methods
- Second-chance mode
Copy Strategies
An argument may be side-effected between the method entry and the point of the failure in the method. Copying strategies:
- Reference: copying only the reference to the argument.
- Shallow: copying the argument itself.
- Depth-i: copying all the state reachable with \(\le i\) dereferences from the argument.
- Deep-copy: copying the entire state.
Options:
- Used-fields: deeper copying on fields that are used (read or written) in the method.
ReCrash always uses the reference strategy for immutable parameters.
Monitoring Fewer Methods
Dosen't monitor methods that cannot be used in the generated tests, or are unlikely to expose problems.
- non-public methods
- empty methods
- simple methods such as getters and setters (no more than 6 opcodes)
Second-chance Mode
- ReCrash initially monitors no method calls.
- Each time a failure occurs, ReCrash enables method argument monitoring for all methods found on the stack trace.
- Efficient, but requires a failure to be repeated twice. If the developer doesn't mind missing the first time a failure happens, and the failure occurs relatively often, second chance mode is a good fit.
Question: could recording all inputs provided to the program be used in tandom with second-chance mode (such that the failure is probable to happen the second time)?
Test Generation Phase
ReCrash generates a test for each of the methods in the shadow stack.
- Restores the state of the arguments that were passed to a method.
- Invokes the method the same way it was invoked in the original execution. Only tests that end with the same exception as the original failure are saved.
- Storing more than one test that ends with the same failure is useful. Some tests reproduce a failure, but would not help the developer understand, fix, or check her solution.
Experimental Study
Subject programs:
- Javac-jsr308: the OpenJDK Java compiler, extended with JSR308 ("Annotations on Java Types"), with four crashes provided by the developers.
- SVNKit: a subversion client, with three crash examples from bug reports.
- Eclipsec: a Java compiler included in the Eclipse JDT, with a crash found in the Eclipse bug database.
- BST: a toy subject program used by Csallner in evaluating CnC, with three crashes found by CnC.
Experimental Study
For each subject program:
- Run PIDASA for parameter immutability classification.
- For different argument copying strategies, with and without second-chance mode:
- Run ReCrash on inputs that made the subject programs crash.
- Count how many test cases reproduced each crash.
Question: how useful would ReCrash be in reality where it is unknown whether the subject projects could crash, and which inputs would make the subject programs crash?
Experimental Study
Research questions:
- How reliably can ReCrashJ reproduce crashes?
- What is the size of the stored deep copy of the shadow stack?
- Are the tests generated by ReCrash useful for debugging?
- Like a case study: an analysis of two crashes, and comments from developers
- What is the overhead (time and memory) of running ReCrash?
Aspects assessed:
- different argument copying strategies
- with and without second-chance mode
How reliably can ReCrash reproduce crashes?
ReCrash was able to reproduce the crash in all cases.
- For some crashes, every candidate test case reproduces the crash.
- For other crashes, only a subset of the generated test cases reproduces the crash.
In most cases, simply copying references is enough to reproduce crashes. In other cases, using the shallow copying strategy with used-fields was necessary.
What is the size of the stored deep copy of the shadow stack?
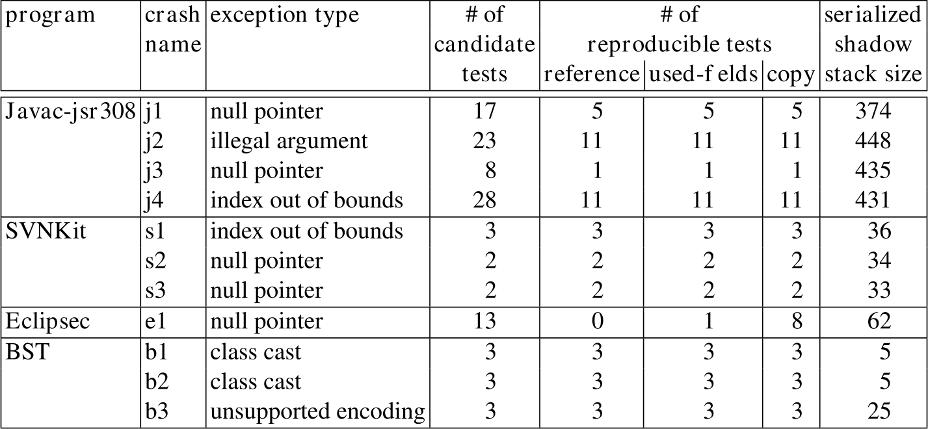
Question: why isn't it compared with the program size and the program memory usage?
An analysis of two crashes
Eclipsec bug e1:
- Eclipsec crashes in callee
canBeInstantiatedbecause an earlier if statement in the callerresolveTypefailed to set a boolean flaghasErrorto true. - The test case for
canBeInstantiatedwill reproduce the crash, but is not helpful. - Demonstrates importance of generating tests for multiple methods on the stack.
Javac-jsr308 bug j4:
- Compiling source code containing an annotation with too many arguments results in an index-out-of-bounds exception in method
visitMethodInvocation. - The generated test does not require the whole source code and encodes only the necessary minimum to reproduce the crash.
- Useful when the compiler crash happens in the field, and the user cannot provide the entire source code for debugging.
Comments from Developers
We gave the tests for j1-4 to two Javac-jsr308 developers and asked for comments about the tests' usefulness, receiving positive responses.
- I often have to climb back up through a stack trace when debugging. ReCrash seems to generate a test method for multiple levels of the stack, making it useful.
- I find that you wouldn't have to wait for the crash to occur again useful.
- When I set a break point, the break point maybe be executed multiple times before the error. Using ReCrash, I was able to jump (almost directly) to the necessary breakpoint.
Question: Why only analyze two crashes and ask only two developers?
What is the overhead (time and memory) of running ReCrash?
Time overhead
Non second-chance mode:
- Copying only the references can be expensive (11%-42%), and shallow copying with used-fields is similar (13%–60%). Usable for in-house testing.
- Deep copying is completely unusable (12,000%-638,000%).
Second-chance mode:
- A barely noticeable 0%–1.7% under copying only the references and shallow copying with used-fields, after a crash has already been observed.
What is the overhead (time and memory) of running ReCrash?
Memory overhead
Non second-chance mode:
- 0.2M–4.7M (2.6%-90.3%) under shallow copying with used-fields.
Second-chance mode:
- negligible
Conclusions
ReCrashJ is usable in real software deployment
- Simple to implement
- Scalable
- Generates simple, helpful test cases that effectively reproduce failures
- Time and memory overhead (13%–60%, 2.6%-90.3%) under non second-chance mode and shallow copying with used-fields usable for in-house testing
- Extremely efficient under second-chance mode